系统的可靠性越高,平均无故障时间越长。系统的可靠性越高,平均无故障时间越长。Linux集群的高可用性,对服务器正常运行起着至关重要的作用。
计算机系统的可靠性用平均无故障时间(MTTF)来度量,即计算机系统平均能够正常运行多长时间,才发生一次故障。系统的可靠性越高,平均无故障时间越长。可维护性用平均维修时间(MTTR)来度量,即系统发生故障后维修和重新恢复正常运行平均花费的时间。系统的可靠性越高,平均无故障时间越长。计 算机系统的可用性定义为:MTTF/(MTTF+MTTR) * 100%。由此可见,计算机系统的可用性定义为系统保持正常运行时间的百分比。
计算机产业界通常用如下表所示的"9"的个数来划分计算机系统可用性的类型。
|
可用性分类
|
可用水平
|
每年停机时间
|
|
容错可用性
|
99.9999
|
< 1 min
|
|
极高可用性
|
99.999
|
5 min
|
|
具有故障自动恢复能力的可用性
|
99.99
|
53 min
|
|
高可用性
|
99.9
|
8.8 h
|
|
商品可用性
|
99
|
43.8h
|
通过硬件冗余或软件的方法都可以从很大程度上提高系统的可用性。硬件冗余主要是通过在系统中维护多个冗余部件如硬盘、网线等来保证工作部件失效时可 以继续使用冗余部件来提供服务;而软件的方法是通过软件对集群中的多台机器的运行状态进行监测,在某台机器失效时启动备用机器接管失效机器的工作来继续提 供服务。
一般来说,需要保证集群管理器的高可用性和节点的高可用性。Eddie、Linux Virtual Server、Turbolinux、Piranha和Ultramonkey 都采用了类似于图1的高可用性解决方案。
图1 高可用性解决方案示意图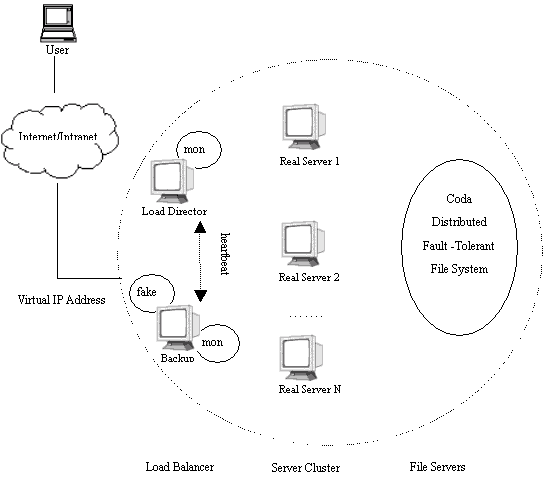
集群管理器的高可用性
为了屏蔽集群管理器的失效,需要为它建立一个备份机。主管理器和备份管理器上都运行着heartbeat程序,通过传送诸如"我活着"这样的信 息来监测对方的运行状况。当备份机不能在一定的时间内收到这样的信息时,它就******fake程序,让备份管理器接管主管理器继续提供服务;当备份管理器又从 主管理器收到"我活着"这样的信息时,它就使fake程序无效,从而释放IP地址,这样主管理器就开始再次进行集群管理的工作了。
节点的高可用性
节点的高可用性可以通过不断监视节点的状态以及节点上的应用程序的运行状态来实现,当发现节点已经失效时,可以重新配置系统并且将工作负载交给 那些运行正常的节点来完成。如图1所示,系统通过在集群管理器上运行mon精灵程序来监视集群中的实际服务器上的服务程序的运行状况。例如使用 fping.monitor 以一定的时间间隔来监视实际服务器是否还在正常运转;使用http.monitor 来监测http服务,使用ftp.monitor来监测ftp服务等等。如果发现某个实际服务器出了故障,或者是其上的服务已失败,则在集群管理器中删除 有关这个实际服务器的所有规则。反之,如果不久以后发现系统已经重新能够提供服务,则增加相应的所有规则。通过这种方法,集群管理器可以自动屏蔽服务器和 其上运行的服务程序的失效,并且当实际服务器正常运转时能将它们重新加入到集群系统中。





